背景
在分布式业务的开发环境中,需要做内部测试甚至引入部分客户做前期使用调研,同时业务的稳定性不够好,所以经常会需要查看业务日志来进行debug/调优
如果是单点测试还好,如果是涉及多机器的分布式业务,那这个查日志的过程就会非常痛苦,这时候,引入日志收集系统就是很自然的想法
但传统的日志收集系统部署较为浪费时间、经历,尤其在多个机器上部署业务很有可能遇到各式各样的依赖等问题,对开发精力的占用有时候甚至让这份努力显得有些得不偿失…
值得庆幸的是,目前流行的日志收集系统组建基本已实现容器化,而借助docker搭建就能摆脱各式依赖的麻烦,使得整个部署过程容易很多
这篇文章介绍了在开发环境使用docker搭建日志收集系统的一些经验,包括架构的说明、选型的原因、部署的过程、相关配置的修改、实践中的一些tips等等
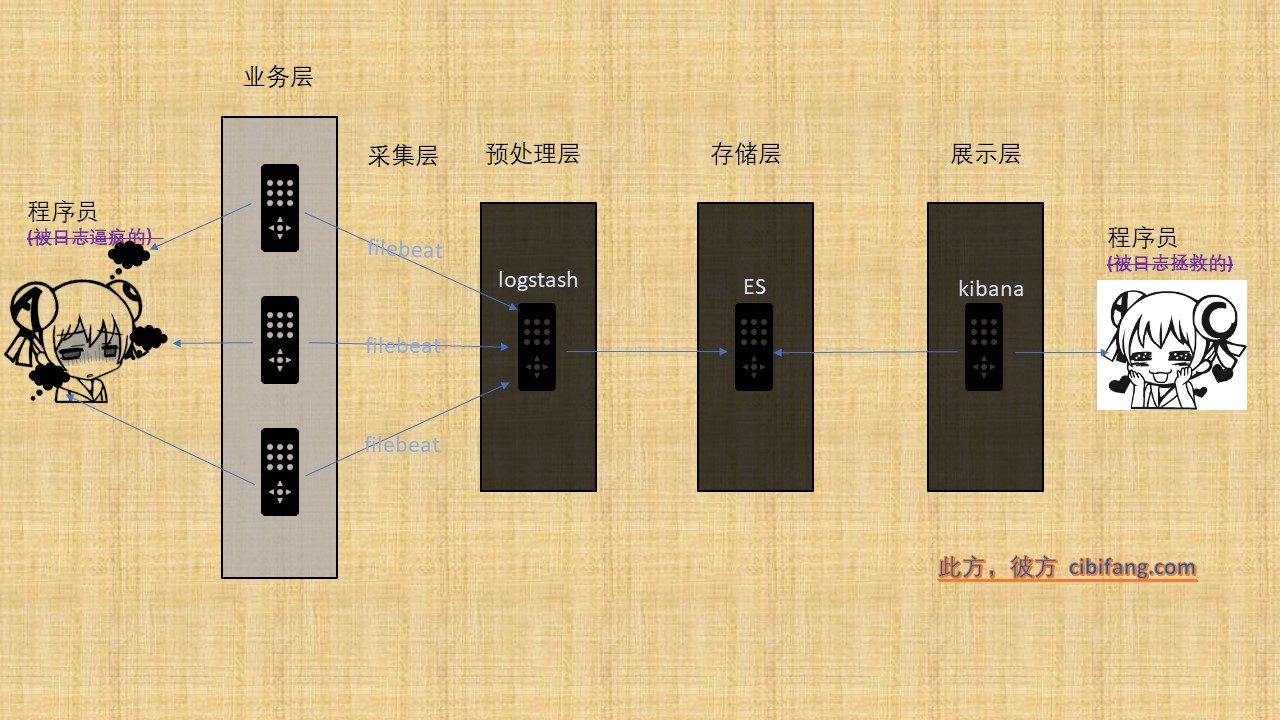
架构
因为是开发环境,所以架构相对简单,一共有四层,如图所示:
实际业务环境中,可能需要根据数据量增加kafka作为数据中转;ES可能需要集群化;更大的数据量考虑引入hbase
- 数据采集层
即为各个业务节点,采用fluentd和docker本身的映射设置将需要传输的日志放在特定目录中;
然后使用filebeat采集指定目录的日志,并且发送到远端logstash上 - 数据转发、预处理层
logstash收到filebeat传输的日志之后,根据自定义规则对日志进行预处理,然后将数据转发到elasticsearch中去
-
数据存储层
elasticsearch会存储收到的数据
-
数据展示层
kibana连接elasticsearch开放的接口,对日志数据做展示,同时处理数据检索请求
涉及的软件
-
filebeat
轻量的数据收集工具。收集数据,做一些简单的处理,之后发送到logstash进行数据进一步处理
-
fluentd
开源的数据收集器,目前有超过 500 种的 plugin,可以连接各种数据源和数据输出组件,在这里主要用于获取docker的标准日志输出
-
logstash
数据收集与处理工具。用于接收来自filebeat的数据,进行数据格式化,然后发送到elasticsearch。由于logstash是运行在jvm上,所以相比filebeat,会消耗更多资源
-
elasticsearch
数据持久化与搜索。负责接收来自logstash的数据,然后保存
-
kibana
数据统计可视化工具。将elasticsearch中的数据,通过图表等进行展示
架构相关的tips
-
docker容器日志收集工具的抉择
目前比较流行的有3种方式:
- 直接通过filebeat去docker的运行目录搜集
- 使用logspout
- 使用fluentd
直接去docker的运行目录采集第一个被pass,通过命令查找到docker的服务运行目录(通常是一长串随机字符),然后去那个目录搜集感觉太过geek了….
logspout默认收集所有docker服务的日志,而fluentd则是根据自己需要在需要收集日志的docker容器启动命令中做配置;对我来说后者更符合需求一些,所以最后选择了fluentd,大家按照自己的需求来选择就可以了 -
日志采集工具的抉择
最早的时候一般直接使用logstash采集,但是logstash存在系统资源占用的问题,所以后来Flume成了更广泛的选择;
而filebeat则是之后涌现出的更为轻量化的收集工具
就目前来看,如果没有什么历史包袱的话,一般的采集会采用filebeat,之后再使用logstash对搜集到的日志做预处理 -
单点部署的elk
这里,logstash/elasticsearch/kibana是部署在同一台机器上的,如果日志量很大,会有性能上的问题,同时也有单点故障的可能性;
但是对于开发环境来说,单点的性能一般就够用了,而且也能够接受这种故障的可能性;
如果是生产环境,这里就必须考虑搭建ES集群来提升性能,同时避免单点故障的问题了;
如果日志量极大的话,还要进一步考虑引入hbase用于持久化存储 -
关于消息队列
如果节点数量很多,日志量很大,那么就需要考虑引入消息队列来提升容错性;
一般常见的方案是kafka + zookeeper; 不过开发环境不需要担心这个问题
部署
ElasticSearch
- 我安装时最新的版本
docker pull docker.elastic.co/elasticsearch/elasticsearch:6.3.1
- 安装注意事项
在elasticsearch的docker安装文档中,官方提到了vm.max_map_count的值在生产环境最少要设置成262144。设置的方式有两种:
- 永久性的修改,在/etc/sysctl.conf文件中添加一行
$ grep vm.max_map_count /etc/sysctl.conf # get current value vm.max_map_count=262144 # change or add - 对于正在运行的机器
sysctl -w vm.max_map_count=262144
- 启动命令
因为没有看到除了同样安装在本机的kibana和logstash之外我有直接调用elasticsearch的可能性,没有暴露9300端口,9200也只是绑定与127.0.0.1上
docker run -p 127.0.0.1:9200:9200 --name elasticsearch -e "discovery.type=single-node" docker.elastic.co/elasticsearch/elasticsearch:6.3.1
前面提到过,这里是单点安装的,如果有拓展需求,则更改single-node参数并增加集群配置;
同时,如果有日志持久化需求,则需要考虑把data目录挂载在本机,或者直接和HDFS结合使用
kibana
- 我安装时最新的版本:
docker pull docker.elastic.co/kibana/kibana:6.3.1
- 启动命令
和es直接配合,所以使用–link参数和elasticsearch链接起来;暴露5601端口用于外部访问及调取数据
docker run -d -p 5601:5601 --link elasticsearch -e ELASTICSEARCH_URL=http://elasticsearch:9200 --name kibana docker.elastic.co/kibana/kibana:6.3.1
logstash
- 我安装时最新的版本:
docker pull docker.elastic.co/logstash/logstash:6.3.1 - 启动命令
需要有一些自定义配置,所以-v挂在了conf出去;同时-p暴露了5043端口接收filebeat的message推送
docker run --rm -it --name logstash --link elasticsearch -d -p 5043:5043 -v /usr/local/elk/conf/logstash.conf:/usr/share/logstash/pipeline/logstash.conf docker.elastic.co/logstash/logstash:6.3.1其中,
/usr/local/elk/conf/logstash.conf是配置的地址,我使用的配置如下:input { beats { port => "5043" } } filter { if [fields][doc_type] == 'docker' { grok { match => { "message" => "%{TIMESTAMP_ISO8601:logtime} %{NOTSPACE:label} %{GREEDYDATA:request}"} } date { match => ["logtime", "ISO8601"] target => "@timestamp" } json { source => "request" target => "parsedJson" remove_field => ["request"] } mutate { add_field => { "request" => "%{[parsedJson][log]}" "container_id" => "%{[parsedJson][container_id]}" } } } if [fields][doc_type] == 'gortc' { grok { match => { "message" => "%{TIMESTAMP_ISO8601:logtime} %{LOGLEVEL:level} %{NOTSPACE:label} %{GREEDYDATA:request}"} } date { match => ["logtime", "ISO8601"] target => "@timestamp" } } } output { stdout { codec => rubydebug } elasticsearch { hosts => [ "elasticsearch:9200" ] index => "%{[fields][doc_type]}-%{+YYYY.MM.dd}" } } - 配置说明
input用于标明输入,这里指定了5043端口,用于接收filebeat传输过来的数据
然后使用filter块对日志内容进行预处理
可以看到,这里使用[fields][doc_type]把日志区分成了docker和gortc两类,这个字段是在filebeat中指定的,用于区分不同类型的日志,之后在filebeat那里再详细说明其中,docker日志是docker服务吐出的日志,这里对它作了4层处理:
docker日志是使用fluentd采集的,采集来的格式默认为
$timestamp$label $json格式,其中,$timestamp是docker吐出日志的时间,$label是fluentd的配置中我们自行指定的,$json是json格式的日志主题示例日志
2018-07-24T00:00:23+00:00 gortc {"log":"2018/07/24 00:00:23.924707 session.go:294: keepalive: session `8641382376390545` send a keepalive [gzdvipfp7nrdl6n1@rtc.test.com] [8641382376390545]","container_id":"59c3b2f2b13bbc4c01dffec614bf16056bf2f13a4ae35820c3d34881434fd21b","container_name":"/gortc","source":"stderr"}- grok模块使用正则把日志主体(
message字段)拆分为logtime/label/request三个字段
> 值得提醒的是,正则在书写的时候务必注意tab和空格的区别,比如fluentd吐出来的日志,时间戳、标签、json格式正文之间就是以tab间隔的,我自己在测试的时候花了很长时间debug这个问题 - data模块使用
logtime字段对日志的@timestamp字段进行了重新赋值
> 注意,这个处理很重要:之后kibana会使用@timestmap属性对日志进行时间排序,而默认情况下的@timestamp属性会是filebeat传输日志的时间,最后导致的结果就是日志的时序混乱,一个时序混乱的日志有什么作用可想而知 - json模块对
request字段进行json解码 - 最后mutate模块把
request/container_id字段分别赋值为之前json字段解析出的json串里log和container_id的键值
在经过这4层处理之后,logstash中保存的日志格式就变成下面这个示例这样的了:
{ "_index": "docker-2018.08.05", "_type": "doc", "_id": "lrcCC2UB4q2qcocu5Twb", "_version": 1, "_score": null, "_source": { "parsedJson": { "container_name": "/gortc", "log": "2018/08/05 16:54:17 http: TLS handshake error from 125.212.217.215:54490: tls: unsupported SSLv2 handshake received", "container_id": "efd15bbb8272f344525bd25a1d88d92438a6426c6510690c9bffeaf375b98808", "source": "stderr" }, "label": "gortc", "beat": { "name": "dts_lf1", "hostname": "e2c86ded2778", "version": "6.3.1" }, "message": "2018-08-05T16:54:17+00:00\tgortc\t{\"container_id\":\"efd15bbb8272f344525bd25a1d88d92438a6426c6510690c9bffeaf375b98808\",\"container_name\":\"/gortc\",\"source\":\"stderr\",\"log\":\"2018/08/05 16:54:17 http: TLS handshake error from 125.212.217.215:54490: tls: unsupported SSLv2 handshake received\"}", "offset": 1219, "container_id": "efd15bbb8272f344525bd25a1d88d92438a6426c6510690c9bffeaf375b98808", "@version": "1", "request": "2018/08/05 16:54:17 http: TLS handshake error from 125.212.217.215:54490: tls: unsupported SSLv2 handshake received", "@timestamp": "2018-08-05T16:54:21.582Z", "fields": { "doc_type": "docker" }, "logtime": [ "2018-08-05T16:54:17+00:00", "2018-08-05T16:54:17+00:00" ], "tags": [ "beats_input_codec_plain_applied", "_dateparsefailure" ], "host": { "name": "dts_lf1" }, "source": "/var/lib/fluentd/logs/docker.b572a5e27cc06276f0ec7ad97c778b0c0.log" }, "fields": { "@timestamp": [ "2018-08-05T16:54:21.582Z" ] }, "sort": [ 1533488061582 ] }gortc日志则是一个标准的日志格式,相对简单很多,所以只使用了2层filter,大家可以根据上面docker日志的解析自己看看能不能看明白它的意思
最后是output块,指定将预处理后的日志吐出到elasticsearch中去
- grok模块使用正则把日志主体(
fluentd
- 镜像
docker pull fluent/fluentd相对于其他服务,fluentd要相对麻烦一点,如果你有一些插件上的需求,就无法直接使用官方的镜像,必须自己搭建自己的镜像才可以
举例来说,如果docker吐出的日志中是多行的(即业务日志中有换行符),那么通过原生fluentd收集到的日志就是多行的;这些日志在通过filebeat传输到logstash之后,已经有了乱序的可能性,所以必须在收集时就做好多行合一的处理;
原生的fluentd又无法通过配置完成这种处理,必须依赖第三方的插件fluent-plugin-conca
这时候我们就必须搭建自己的镜像了值得安慰的是,自建镜像并不是很麻烦,可以参考这篇官方blog
如果你只有日志多行合一的这一个需求的话,也可以直接使用我建好的镜像,github地址 -
启动命令
docker run -d --rm --name fluentd -p 127.0.0.1:24224:24224 -p 127.0.0.1:24224:24224/udp -v /tmp/fluentd/logs:/fluentd/log -v /usr/local/fluentd/conf:/fluentd/etc -e FLUENTD_CONF=fluent.conf cibifang/fluentd:v1.2其中/tmp/fluentd/logs是宿主机存放fluentd吐出日志的位置
/usr/local/fluentd/conf是存放自定义配置的位置,我使用的配置如下:<source> @type forward @id input1 @label @mainstream port 24224 </source> <label @mainstream> <filter **> @type concat key log multiline_start_regexp /^(?>\d\d){1,2}[/-](?:0[1-9]|1[0-2])[/-](?:(?:0[1-9])|(?:[12][0-9])|(?:3[01])|[1-9]) (?:2[0123]|[01]?[0-9]):?(?:[0-5][0-9]):?(?:(?:[0-5]?[0-9]|60)(?:[:.,][0-9]+)?)/ </filter> <match **> @type file @id output_docker1 path /fluentd/log/docker.*.log symlink_path /fluentd/log/docker.log append true time_slice_format %Y%m%d time_slice_wait 1m time_format %Y%m%dT%H%M%S%z </match> </label> - 配置说明
首先是source块,比较简单,需要注意的是
port和label
port指定了接收输入的端口,这个我们之后会用到
label则对应于下面的label块,标识着我们对这个source块对应的消息全部使用mainstream这个label块来处理这里需要注意的是,如果你指定了label,那么就只有对应label的filter规则会生效
在我自己开发的时候,我一度以为label之外属于全局规则,结果花了很长时间debug…个人不是很理解这个设定= =在对应label中,可以看到filter和match两个处理块,都着急使用了
**来进行匹配,即匹配全部日志,如果你有过滤需求的话,对这里进行相应修改就可以了
其中,filter块就使用了之前提到的concat插件,对多行日志进行了合一,这里是通过指定正则识别为多行开始的方式来做合一的在官网建议的配置中有一条
stream_identity_key container_id
经过查询concat plugin的README,它的作用是区分日志具体归属于哪个服务
但我在测试时时发现,如果配了这个的话,部分日志的多行合一会失效…
这很奇怪,我自己查log试图找到失效的规律,但是没有什么发现;换了container_name作为key值结果也是一样…
如果你知道这是怎么回事的话,希望能评论说一下原因,非常感谢~match块中指定了输出日志的位置
-
对应的docker启动参数
启动fluentd之后,对于想要通过fluentd采集日志的docker服务,需要在启动时添加对应参数,这里给一个示例
docker run -d --rm -p 8080:8080 -p 2539:2539 \ --log-driver=fluentd --log-opt fluentd-address=127.0.0.1:24224 --log-opt tag="gortc" \ gortc:1.1.10其中,需要注意的是
--link fluentd --log-driver=fluentd --log-opt fluentd-address=127.0.0.1:24224 --log-opt tag="gortc"这5个参数,其中- link参数用于链接fluentd容器,其实并不必要,因为之前已经暴露fluentd端口了,而且在之后的参数中也是使用暴露的端口进行通信的
- log-driver指定容器的日志采用fluentd来收集
- log-opt fluentd-address 指定了fluentd的地址
- log-opt tag 则是对这个容器吐出的日志加了对应的标签,这个是可选的,但建议还是加上比较好,我们在Logstash的解析中也使用过这个label,还记得吗?
filebeat
- 我安装时最新的版本
docker pull docker.elastic.co/beats/filebeat:6.3.1 - 启动命令
docker run --name filebeat -d --rm -v /usr/local/filebeat/conf/filebeat.yml:/usr/share/filebeat/filebeat.yml -v /tmp/fluentd/logs:/var/lib/fluentd/logs -v /tmp/gortc/logs:/var/lib/gortc/logs docker.elastic.co/beats/filebeat:6.3.1这个配置很简单,挂载出去三个地址,其中
/tmp/fluentd/logs和/tmp/gortc/logs是需要收集的日志地址,/usr/local/filebeat/conf/filebeat.yml则是自定义的配置文件
自定义配置如下:name: "dts_cz2" filebeat.prospectors: - paths: - /var/lib/fluentd/logs/*.log fields: doc_type: docker - paths: - /var/lib/gortc/logs/*.log fields: doc_type: gortc output.logstash: hosts: ["$ip:5043"] - 配置说明
首先是
name字段,大多数教程中并不会配置这个字段,但在实践中这个字段还是很有用的;如果没有这个字段,filebeat默认的hostname会是一个随机字符串;最后在kibana中,想要区分来自不同机器的日志很方便,但想要更明确地知道来自与哪一台机器就很不直观了接着两个
paths指向了2个不同的log地址
还记得’doc_type’这个字段吗?就是在logstash中用到的那个,就是在这里设置的啦~最后是对
output的设置,这里直接指向之前logstash暴漏的ip+端口(示例中的$ip就是logstash所在的ip)
最终效果
到这里为止,整个日志收集系统就完全搭建好啦~
下面发一下日志收集好后,在kibana查看的效果图:
应该说,整个系统的构建里,如果不去考虑一开始选型、调研、研究配置的时间,花的时间是非常少的
如果不是使用docker的话,花在实际部署以及莫名其妙bug调试上的时间精力一定不会比之前这些工作少的(最难受的在于,前面的这些选型、调研、研究配置都是相对有用的经验,而实际部署和调试仅仅只是”体力劳动”,收获很少消磨时间精力却一点不打折扣)
感谢容器时代让苦逼的我们极大程度上从那种无益劳动中解脱出来~
相关
- 分布式日志跟踪实践
如果你的服务没有做分布式日志跟踪处理的话,你可能会发现,把日志全部收集到一起唯一节省的只有你登陆机器的时间,查日志、定位问题依然非常痛苦,甚至能同时看到所有机器的日志让你感受到翻倍的痛苦
分布式日志跟踪系统会帮助你在服务中加入可用于跟踪的标识,结合kibana的检索功能+这些标识,流程的梳理和问题的定位就会无比清晰啦
这么说吧,对于分布式业务来说,日志跟踪系统和日志收集系统单独都能提升一部分体验,但结合之后,你会发现一切都有了质的变化;如果你负责的业务还没有做,大可以在开发环境中尝试一下哦~
然后上面这篇blog是之前在直播系统中引入分布式日志跟踪系统的经验,希望能给你一些帮助啦~ -
分布式日志跟踪系统的基本原理是在日志中添加标识,这种跟踪标识最好是添加在后缀之中,而非常适合分布式业务的golang语言的标准日志库并没有提供后缀接口,这篇blog中介绍了一种简单的实现方法
参考
-
这篇博客简要介绍了通过docker搭建ELK日志系统的步骤;如果不是用于开发/线上环境,仅是自己搭单节点的来测试玩玩,看这篇就差不多够了
-
Logstash中grok filter example例子
这篇文章介绍了logstash的filter,尤其是对于grok的说明非常有学习、参考价值
-
这篇文章介绍了logstash的日期处理,在我的例子中很有用,因为filebeat自动打上去的@timestamp是不符合需求的,我们需要的是日志中的日期
-
How to parse json in logstash /grok from a text file line?
这是stackoverflow中的一个问答,涉及到在logstash中如何处理json的问题
-
logstash/grok-patterns at v1.4.2 · elastic/logstash
这个github文件里是一些logstash grok中常用的正则,如果你是真的要用于开发、线上,那这个会非常有用
-
fluentd的官网说明,里面关于多行的处理真的非常有用!老实说,即使是google也搜不到比这个更好的答案了,这是我印象中最良心的官网说明,竟然说到这么细节
拓展
-
ELK+Filebeat+Kafka+ZooKeeper 构建海量日志分析平台
从架构的角度分析了日志收集系统构建的思路,非常值得阅读,推荐!
-
这篇文章介绍了日志解决方案的常见架构及部分问题的解决方案,虽然比较简略,但也很值得阅读
发表评论