背景
什么是 分布式跟踪系统
当代网络服务通常是一个复杂、大规模的分布式系统,其中往往嵌套着多个互相协作的子系统。
为了对这些子系统之间的调用链、依赖关系等进行跟踪, 分布式跟踪系统应运而生。
当前分布式跟踪系统的理论基础基本都来自于Google Dapper这篇论文。
而其中使用最广泛的开源架构,则是twitter的zipkin.
这篇文章主要介绍在直播分发系统中引入zipkin的实践历程。
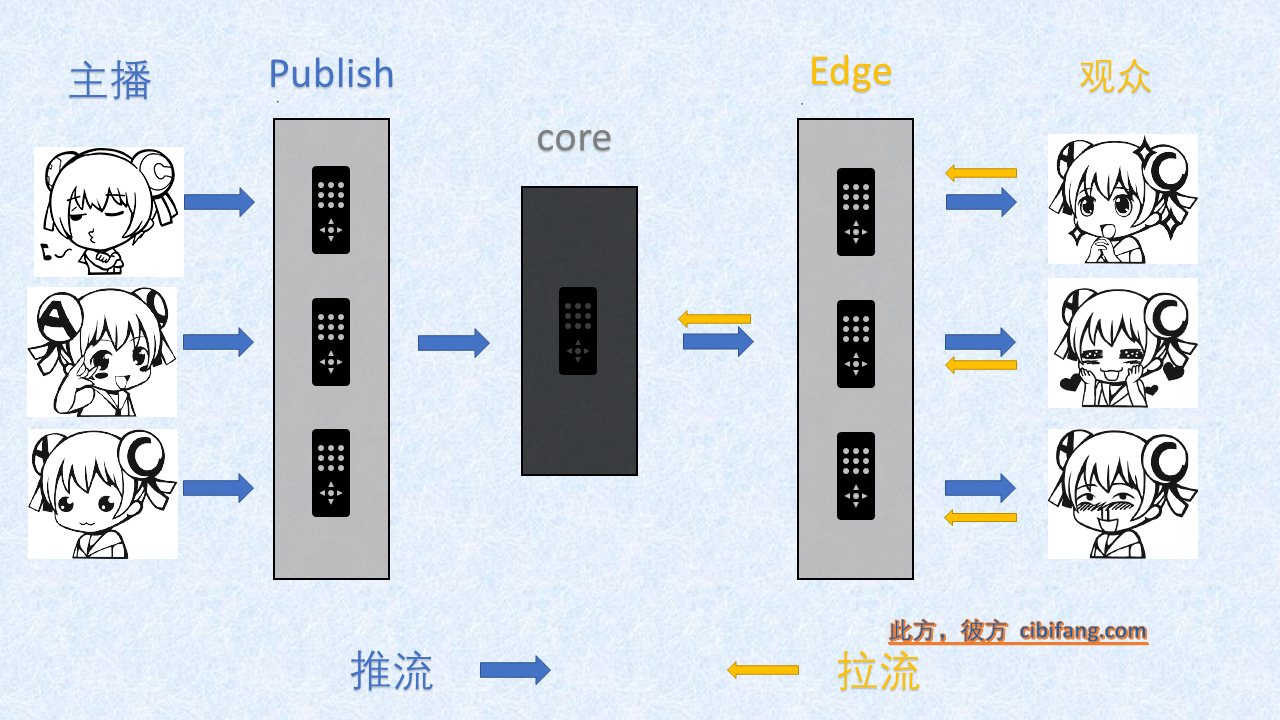
直播分发系统常见架构
直播,近年来开始流行并迅速成为大众所喜闻乐见的一种娱乐形式。
主播的影像能够实时、流畅的传达到每一位观众的面前,背后是一整套的分布式视频流分发系统。
业界目前通行的直播分发架构中,一般分为上行/下行两种流程,角色架构分为3-4层;
其中,上行指主播推流流程,下行指观众拉流流程。
角色架构如下:
- publish
上行流程中的基础节点,负责接收主播推流,然后转推到核心节点。 - core
上行、下行流程的结尾,作为直播流的中转中心。 - edge
下行流程中的基础节点,负责接受观众拉流,然后自己会去core拉流。
- 有的时候,因为部分edge节点到core的质量可能不好,在edge和core之间会有一个parent层,edge去parent拉流,parent去core拉流。
- 一些转码、录像的服务,一般可以考虑在publish和core上做转推等方式实现
直播分发架构中 分布式跟踪系统 的作用
在直播架构中,分布式跟踪系统主要有两个作用:
- 记录直播流在系统中的链路时间点,为之后的数据分析/指标调优提供基础数据;
-
串联流在不同层之间传递的日志,帮助运维/开发人员调试具体的问题
- 就个人的经验,第一点在实践中被大大的忽视了;
举一个实际发生过的例子,一个对流媒体协议以及服务器编程很熟悉的开发,可能会想到一个很棒的主意,利用一个缓存策略让每一路拉流可以节省一次业务服务器的请求,让首屏速度平均能够提升十几ms,但要付出的代价是增加业务复杂度+一次全站更新;
但是如果能简单分析一下链路数据,很可能发现只要更改一下对于错误流的处理策略,首屏速度能够提升几十甚至上百ms,而只需要修改一个简单的配置。这里那位开发提出的主意不够好吗?已经很好了,十几ms的提升看起来小,但是厂商之间的差距可能就是由这些小的优化产生的。
但是对于一个一直“粗放管理”的系统来说,引入分布式链路跟踪+数据分析,能够带来的提升会是更加明显的。更普遍的,相对于单节点、单层的孤立的数据分析,链路分析在以下领域都有更直接也更强的作用:
- 拓扑形态分析:直观的看到整体的调用拓扑,分析异常调用
- 依赖关系分析:识别易故障点/性能瓶颈、强依赖等问题
- 容量估算:根据链路调用比例、峰值QPS评估容量
- 节点质量分析:通过集群中数据的统计寻找表现异常的节点
- 第二点的重要性则视环境而有所不同
如果平台稳定性很好,数据分析-展示系统足够完善,那么具体的业务日志重要性就不是那么大,将它们串联也就只是一个锦上添花的作用
但如果平台并没有那么成熟,运维甚至开发要花很多时间在定位、解决线上bug上面,那么一个日志收集系统+链路跟踪提供的串联,能够节省的时间、经历会是很可观的。除此以外,很多数据分析层面看到的问题,找具体的业务日志跟踪几个、十几个实例再看一看,很可能能有更大的收获,比单纯看着数据然后根据“经验”猜原因要有效的多。
这里吐槽一下,不重视链路跟踪+数据收集/分析然后根据“经验”猜测来进行优化见得多了,
还可以理解为历史遗留问题;有了数据之后看到数据里揭示的问题,又不愿意去查些实际的业务日志,
而是空想原因然后直接给结论,这种也不少见呀(也要自我警醒一下)
系统架构
和通常的分布式跟踪系统一样,主要分为3个部分:
- 数据埋点
- 数据收集
- 前端展示
因为采用了zipkin的关系,最后的前端展示可以直接使用zipkin的展示页面;
但zipkin的展示对于直播这种长连接不是佷适用,建议有精力的话自己写一个展示界面
基本概念
简单理解一下zipkin,它是一套日志规范+一套对符合规范的日志的收集、分析、展示系统。
所以如果要使用它,首先要对这套日志规范中的几个基本概念有所认知:
- traceId
用于标识一整次跟踪,应该保证全局唯一,在整个跟踪过程中传递,在直播中一般由主播的推流或者观众的拉流发起
- spanId
用于标识一次跟踪中的某一个调用阶段,规则和traceId一样,第一个调用的spanId应该和traceId保持一致
-
parentId
上一个调用阶段的spanId,每次跟踪的第一层该值为空
-
annotation
时间戳相关的业务信息。
zipkin默认的有”ss”, “sr”, “cs”, “cr”4种- cs
客户端发起请求,标志Span的开始
-
sr
服务端接收到请求,并开始处理内部事务,其中sr – cs则为网络延迟和时钟抖动
-
ss
服务端处理完请求,返回响应内容,其中ss – sr则为服务端处理请求耗时
-
cr
客户端接收到服务端响应内容,标志着Span的结束,其中cr – ss则为网络延迟和时钟抖动
一般来说,这4个就可以满足基本的需求了
- cs
- binaryAnnotation
键值对形式的业务信息。
数据埋点与收集
埋点与收集一般有两种处理方式:
- 打在独立的日志里,对接分布式日志收集系统
-
通过http等方式实时发送给专门的collector
第一种方式在绝大多数情况下都是完全优于第二种的,不管是资源的占用还是业务复杂度;
第二种我能想到的优点就是实时性更强。
但一般来说分布式日志跟踪对实时性的要求没有那么高,而且日志收集的实时性其实也还可以接受了。
当然走到现实,还是要视自己的业务性质以及需求来决定。
对于直播来说,直接采用第一种就是了:
首先是对于分布式跟踪系统的需求决定了对实时性要求不高;
其次可以直接复用已有的日志收集系统。
埋点位置
建议分为2个阶段来做;
- 阶段1: 只在cs/cr/ss/sr这四个点打日志
具体来说:
- 在收到拉流/推流请求的时候以span1打一条日志(sr)
- 在发出拉流、推流请求的时候打span2一条日志(cs)
- 监测到下游流结束的时候以span2打一条日志(cr)
- 自己流结束的时候以span1打一条日志(ss)
可能稍微有些绕,不过只要理解了client/server区别+cs/ss标识的是处理的结束而不是收到响应,就很容易理解了
这一块对于不熟悉的人来说是重点,尤其注意不要把“处理结束”和“发出、收到响应”搞混
- 阶段2: 在对业务比较重要的各个业务内埋点
对直播来说,举几个例子:
- 发出/发出第一个视频帧
- 收到/发出metadata
- 内部检测到卡顿
还有很多
为什么建议分成2个阶段来做呢?
首先是为了快速上线->看到成果,其次是分成阶段进行有助于版本控制
这个算得上是血泪教训了…
尤其如果开始有一定的试探心理,还不太理解这个业务的重要性以及作用(或者上级不太理解),那么阶段一迅速上线,你就能立刻看到线上的流图;
对于数据分析来说,虽然看起来只有4种埋点,但其实已经可以用来分析首屏时间瓶颈(比较粗略),链路质量等等很多东西了
然后拿着已经有的成果,再来看是否有继续投入资源的必要,会有效很多
对于版本控制来说也是一样,如果只做第一阶段,即使出现什么bug也是很容易fix的,因为涉及的流程本来就不多;
之后一个版本一个版本迭代着上线,进度可控+可见,有bug也可以随时回滚
串联日志
串联日志很简单,记录下span的值,然后加在业务日志后缀上面就可以了,因为span值是全局唯一的,所以根据trace+span值就能串联起链路中的日志了
如果你的服务是golang的,或者你对为什么是放在后缀而不是前缀有疑问,可以看这篇博文golang日志添加后缀,里面介绍了一些相关知识(^-^)
串联日志做好之后,如果你有成型的日志收集系统,那么直接在前端中按照traceId作为key,就可以搜索到一次推流/拉流流程的所有相关日志;再根据spanId和parentId做进一步的检索,整个业务流程就会非常清晰了
数据收集
正常的日志收集就可以,目前比较流行的方案应该是filebeat+kafka+elk,我之后会写一篇开发环境级别的分布式日志收集部署教程,更新在这里
数据分析
对于一些简单的分析规则,直接调用elasticsearch自己的搜索器即可
不过考虑到日后的拓展性,还是建立自己的数据分析pipeline比较好
这方面我还没有相关的经验,很遗憾没有办法做什么分享,希望以后有机会O.O
前端展示
在埋点只维持在阶段1时,使用zipkin作为展示就可以了,效果相对于没有还是可以的
使用也很简单,启动zipkin-server并且指定从elasticsearch(如果你使用了elk)读取数据就可以了
这里展示一下效果:
- 上行推流zipkin展示效果
在上图展示的上行推流流程中,深度有2层,涉及5个span
从深度的角度,192.168.91.4收到推流是第一层,然后分别推流到192.168.91.13和192.168.91.23是第二层
图中的publish涵义为sr,send_connect涵义为cs,ss和cr没有显示出来 -
下行拉流zipkin展示效果
在上图展示的下行拉流流程中,深度有3层,涉及7个span
从深度的角度,192.168.91.9收到拉流是第一层,然后发起拉流请求到一个没记录成功的机器和192.168.91.34是第二层,192.168.91.34发起新的拉流请求到192.168.91.23是第三层
图中的play涵义为sr,send_connect涵义为cs,ss和cr没有显示出来 -
span详情展示效果
是的,前面展示的流程中的那些横条都是可以点开的,点开之后就是上图的效果
我们可以清晰的看到在这个span中每个埋点触发的具体时间点以及一些自定义日志
这个展示效果你觉得怎么样呢?平心而论,如果没有什么定制化的需求,看起来还是可以的
但对于直播系统来说,他还是有很多不足,其中最为明显的一点:
我们可以看到一个span总是相对很长,埋点以及span的触发总是集中在2端,导致在整体的图上没办法很清晰地看到每个埋点的相对时间,需要点开才可以;而中间则是大片什么埋点都没有的空白
这是因为相对于zipkin设计所针对的http调用来说,直播的调用链有深度浅,调用持续时间长的特点
综上所述,如果只需要基本的使用体验(也许对你来说,这个的最重要的地方在于数据分析系统,而不是针对运维的展示),那么zipkin的原生展示界面完全够用了;那么如果想要有更好、更定制化的体验,还是需要自己的前端页面
总结
在直播系统中引入 分布式跟踪系统,说起来你可能不信,这是我刚毕业入职后接触的第一个大型项目,而且差不多是由我独立负责的(从这一点也能看到当时部门对这个项目的重视程度)。
后来因为种种原因,这个系统终于还是没有推到线上…当时只是感觉自己做的东西没有被用到有些不爽,但也没有很在意
之后成了直播部门的开发主力之一,在前期是修遗留的bug修的焦头烂额,中后期是在业务调优中逐渐发现数据分析的重要性…尤其在一次阴差阳错自己对边缘数据自行作了一些简单的处理/分析,结果在业务调优中起到了非常重要的作用之后,对这方面就有了很大的兴趣,也花了很多时间在这方面
这时就越发察觉了分布式跟踪系统的重要性,时常会觉得,如果这系统能够搭建起来,很多都会不一样;但这时候整个直播已经不太重要啦=,=
所以这篇文章其实是一个对失败经验的总结,所以会看到我在重要性以及上线建议上面说了很多,那些啰嗦都是当时调研、部署时的血泪呀QAQ
如果你正要搭一个分布式跟踪系统,尤其是对于一个独立的分布式部署的类似于直播系统这样的系统,而不是分布式跟踪系统本来针对的多种业务混合的那一类,那么这篇文章应该能给你一些帮助
也希望能给你一些帮助,这样我的失败总算就有些实际的作用啦(所以如果有帮到你,务必评论安慰我一下呀)~~~~
拓展阅读
- 分布式调用跟踪与监控实战
阿里鹰眼系统的分享,我看了下时间是17年中才发出来的,写的真的很好,各个方面而言都是的;写这篇博客时翻到这个分享,当时真的要哭出来,这就是我理想中要做出来的效果啊QAQ
如果你是准备做一个自己的分布式跟踪系统,这篇绝对非常有帮助 -
美团分布式系统的分享,相对上一篇来说实话实说是有些差距的…不过人家15年就发出来了,而且分享就是帮助嘛=,=我做项目的时候应该看过这一篇
发表评论